LPG: Understanding the Model Beyond the Market Brands

Table of Contents
1. Introduction
2. Property Graphs and Labelled Property Graphs: A Simple but Important Distinction
3. The Confusion Between Model and Product
3.1 Why LPG ≠ Neo4j (and Neo4j ≠ LPG)
4. Why LPGs Work So Well in Real Systems
4.1. Real Enterprise Environments Are Dynamic
4.2. How LPGs Support Evolving Semantics
4.3. The LPG as the Foundation of Applied Knowledge Graphs
4.4. Why LPGs Are Natural Substrates for GraphRAG
4.5. A Unified Substrate for Modern Knowledge Systems
5. Languages that Shape the LPG Ecosystem: Gremlin, Cypher, openCypher, and GQL
6. Closing Thoughts: The Real Reason LPG Matters
1. Introduction
Graph technologies are rapidly becoming the backbone of modern enterprise systems. They sit behind recommendation engines, anti-fraud platforms, supply-chain optimisation, medical analytics, cybersecurity intelligence, and the new world of GraphRAG retrieval architectures. They power operational knowledge graphs, connect siloed datasets, and increasingly act as the semantic substrate for enterprise AI.
Despite this expanding influence, the fundamentals of graph modelling remain surprisingly misunderstood. Much of the confusion stems from marketing narratives, vendor terminology, and the tendency to treat certain products as if they are the model itself. As a result, many engineers still use the term “LPG” as if it refers to a specific database brand rather than a conceptual modelling pattern. This misunderstanding narrows architectural options, encourages vendor-centric design, and obscures the expressive power of the labelled property graph itself.
This post clarifies what the LPG model truly is, why it should be understood independently from any particular technology, how it differs from the underlying property graph, and how its semantics relate to the graph query languages as Gremlin, Cypher, openCypher, and the ISO-standardised GQL, that shape the modern graph ecosystem. The goal is to provide a clean conceptual foundation for practitioners building enterprise graph systems, Applied Knowledge Graphs, and GraphRAG pipelines.
2. Property Graphs and Labelled Property Graphs: A Simple but Important Distinction
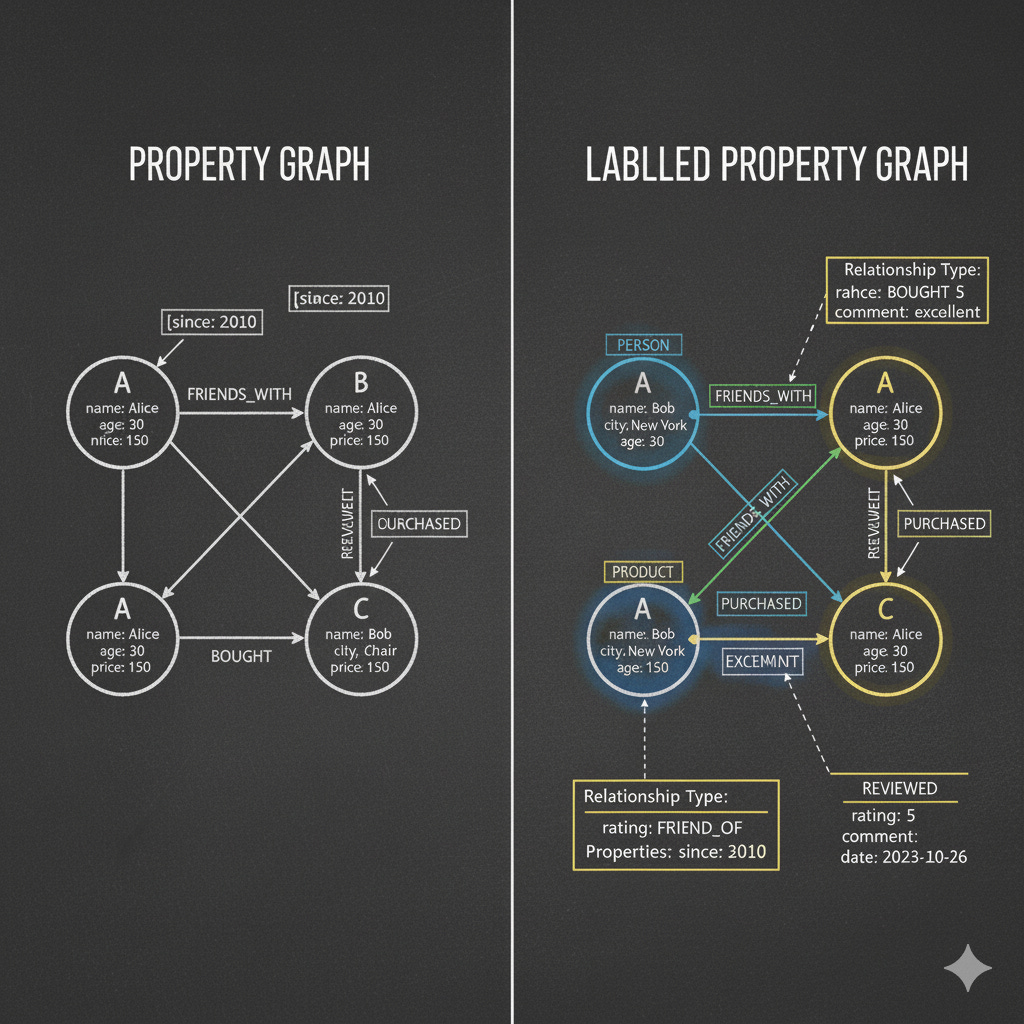
A property graph (PG) is the foundational model used in most modern graph systems. In a property graph, both nodes and relationships can store arbitrary key–value properties. This immediately makes the model far more expressive than classical mathematical graphs because descriptive information is embedded directly into the structure itself. A node might hold attributes like name, age, or embedding_vector, while an edge might describe details such as a timestamp, a weight, or a confidence score.
A property graph, by design, remains neutral. It does not define the type of entity that a node represents, nor does it clarify the meaning of a relationship. The system simply stores nodes, edges, and their associated properties. Any interpretation of this data must be provided by the developer or through application logic. The Labelled Property Graph (LPG) builds on this foundation by introducing two lightweight but meaningful additions:
· Node labels that categorise entities (e.g.,
Customer,Transaction,Product,RiskEvent).· Relationship types that clarify the nature or direction of the connection (e.g.,
PURCHASED,LINKED_TO,GENERATED_FROM,CAUSED).
These labels and types do not replace properties but complement them. Properties still act as fully flexible descriptors capable of holding timestamps, metadata, provenance links, sensor readings, financial indicators, or modern AI signals like embeddings and model-assigned semantics.
Where the property graph provides the raw expressive canvas, the labelled property graph adds a semantic vocabulary. This shift may seem small from the outside, but its impact is significant. By formalising the meaning of entities and relationships, the LPG model provides clarity without rigidity. Teams gain a shared language for describing structure without being forced into heavy ontologies, complex taxonomies, or strict schema governance.
This balance, which provides structure without bureaucracy, explains why LPGs have become the default mental model for engineers building operational knowledge graphs, real-time graph applications, and GraphRAG systems. It is a model where meaning emerges naturally as the domain evolves, and where both humans and machines can reason with data in a way that is intuitive, scalable, and aligned with real-world complexity.
3. The Confusion Between Model and Product
Although simple in principle, the LPG model is frequently misinterpreted through the lens of specific vendor technologies. The most common mistake is equating the LPG concept with Neo4j, as if the model originated from or is defined by the product. This is similar to assuming that Oracle defines the relational model, or that SQL is fundamentally a product of PostgreSQL. In each case, the model precedes and transcends the implementation.
The LPG model is an abstract and vendor-neutral conceptual pattern. It describes how information should be represented, how meaning attaches to structure, and how entities relate. Products implement these ideas, each with its own compromises, performance trade-offs, and extensions. When this distinction is lost, architects inadvertently design systems that reflect a product’s limitations rather than the conceptual openness of the LPG model. This misalignment leads to decisions that are harder to reverse, more expensive to maintain, and less portable across platforms.
3.1 Why LPG ≠ Neo4j (and Neo4j ≠ LPG)
Neo4j is strongly associated with the labelled property graph model because it popularised its usage and provided a developer-friendly language, Cypher, which made graph querying accessible to a broad audience. However, Neo4j is only one implementation among many. It embodies design choices, storage strategies, indexing approaches, and execution models that reflect a particular philosophy, but these choices are not intrinsic to LPGs.
Treating Neo4j as synonymous with the LPG model creates several misconceptions. It implies that other databases using the LPG pattern are somehow derivative or non-standard, when in fact many of them implement the model with different emphases, stronger performance characteristics in certain use cases, or additional features such as distributed processing or streaming ingestion. Systems like Memgraph, JanusGraph (via TinkerPop), AWS Neptune DB, Ultipa, and many others all implement the LPG modelling pattern, while also offering capabilities that differentiate them significantly from Neo4j. Other graph systems, such as ArangoDB or TigerGraph, support property-rich graphs but follow different schema and typing models, and should not be considered strict LPG engines. Furthermore, the openCypher initiative and the emergence of the ISO-standardised GQL language demonstrate that the LPG model has matured far beyond any single product.
For the overviews of the current LPG vendors, please visit these previous posts
Graph Data Science and Analytics Across Graph Vendors for GraphRAG (https://sergeyvasiliev.substack.com/p/graph-data-science-and-analytics)
Vector Embeddings in Graph Databases: Overview and Engine Capabilities (https://sergeyvasiliev.substack.com/p/vector-embeddings-in-graph-databases )
4. Why LPGs Work So Well in Real Systems
4.1. Real Enterprise Environments Are Dynamic
Enterprises do not operate in stable or predictable environments. Regulations change, business processes evolve, partner ecosystems shift, and adversaries or market forces adapt faster than traditional modelling methods can respond. Modern AI introduces additional volatility because embeddings, classifications, clustering signals, and similarity metrics continuously influence how organisations interpret and act on their data.
In such conditions, modelling approaches that require upfront completeness or rigid schema governance quickly become liabilities. The LPG model offers a practical balance between structure and adaptability, allowing knowledge to stabilise only where stability is useful. A previous article, “The Schema Paradox: Why LPGs Are Both Structured and Free” (https://sergeyvasiliev.substack.com/p/the-schema-paradox-why-lpgs-are-both), explores this duality in more detail.
4.2. How LPGs Support Evolving Semantics
A property graph already provides expressive modelling by allowing descriptive attributes on nodes and relationships. The LPG extends this expressiveness by introducing labels and relationship types. These features give engineers a semantic vocabulary that can grow over time. This growth is critical in domains such as anti-money-laundering, supply chain intelligence, operational risk management, identity resolution, cybersecurity, and MLOps observability, where the meaning of events and entities evolves as new evidence appears.
LPGs enable gradual semantic enrichment. New categories of actors, new event types, new risk indicators, and new causal structures can be added without re-engineering existing models. The LPG behaves like a living representation of the domain, reflecting how understanding changes over time rather than how it was originally documented.
4.3. The LPG as the Foundation of Applied Knowledge Graphs
The strengths of the LPG model become most apparent in Applied Knowledge Graph (AKG) environments. An AKG integrates operational facts, reference datasets, behavioural signals, historical knowledge, and AI-derived insights into a single connected structure. This unification allows organisations to represent how their business actually behaves under real conditions. An LPG can express causality, influence, provenance, confidence levels, source lineage, alerts, exceptions, temporal patterns, and multi-event sequences. These capabilities are essential for detecting fraud chains, tracing supply disruptions, uncovering compliance violations, or understanding weak links in operational processes.
In an AKG, the graph becomes a constantly adapting operational mirror of the enterprise. The LPG provides the semantic and structural flexibility required for such a system to remain accurate as reality shifts.
4.4. Why LPGs Are Natural Substrates for GraphRAG
GraphRAG systems depend on the ability to combine symbolic structure with vector-driven similarity. This requires a substrate that can store embeddings, represent semantic categories, capture provenance, version relationships, and incorporate model-generated interpretations while remaining fully inspectable by humans.
The LPG satisfies these requirements. Embeddings become properties. Classification results become attributes. Versioned edges record changing relationships. Provenance metadata supports traceability for AI outputs. The symbolic layer informs retrieval paths, while the embedding layer provides semantic approximation. The result is a unified knowledge space where meaning and similarity co-exist. Retrieval is driven by graph structure, domain semantics, and vector proximity simultaneously. This combination is not just convenient for GraphRAG. It is foundational.
4.5. A Unified Substrate for Modern Knowledge Systems
In practical engineering terms, an LPG allows teams to integrate business attributes, process behaviour, event sequences, textual semantics, operational lineage, and embeddings inside a single coherent model. The graph remains understandable to experts, executable by systems, and adaptable to new insights or signals.
This blend of flexibility, semantic clarity, and operational depth is what makes the LPG indispensable for modern AKG and GraphRAG deployments. It is not merely a convenient model. It is the structure that allows connected knowledge to evolve at the speed of business, regulation, risk, and AI.
5. Languages that Shape the LPG Ecosystem: Gremlin, Cypher, openCypher, and GQL
Graph query languages play a defining role in how engineers interact with LPGs. Each major language family reflects a different philosophy and has contributed to the evolution of graph databases in distinct ways.
Gremlin represents the imperative traversal-based approach. It allows developers to describe the exact sequence of steps taken through the graph. This style is compelling for graph algorithms and pipeline-based transformations but can be harder for newcomers because it requires a procedural mindset.
Cypher introduced a declarative pattern-matching paradigm that significantly broadened adoption. Its ASCII-art syntax makes graph queries visually intuitive and accessible. As Cypher gained popularity, Neo4j published openCypher as an open specification to encourage broader adoption. This was a pivotal moment because it allowed multiple vendors to converge on a common declarative language rather than inventing incompatible dialects.
The evolution continued with the creation of GQL. The first ISO standard graph query language, GQL (ISO/IEC 39075:2024), emerged after a decade of academic and industrial collaboration. Initially explored as part of SQL extensions (SQL/PGQ), the graph query work eventually branched off into a standalone language. GQL formalises a standardised property graph model whose semantics closely align with LPG systems and positions itself as the long-term SQL of the graph world. It is declarative, expressive, and designed for interoperability across vendors.
GQL did not replace Cypher but to unify the conceptual foundations of declarative graph querying. It represents the moment the LPG model became a formally standardised part of the data world.
Across Gremlin, Cypher, openCypher, and GQL, we see the establishment of a shared conceptual and linguistic ecosystem for LPGs, one that spans vendors, storage engines, and workloads.
6. Closing Thoughts: The Real Reason LPG Matters
The increasing adoption of labelled property graphs reflects a broader shift in how organisations structure and use information. Modern enterprises operate in complex ecosystems where relationships, temporal patterns, context, and provenance matter as much as the raw data itself. The LPG model offers a way to capture this complexity without drowning engineers in rigid ontology management or brittle schema design.
Property graphs provided flexibility by embedding attributes directly into nodes and edges. The LPG model advanced this by adding simple but powerful semantic cues that allow humans and machines to interpret the graph meaningfully. openCypher and GQL reinforced this foundation by providing a lingua franca for expressing graph logic, while modern engines expanded how this model can be implemented and scaled.
Most importantly, LPGs form the practical backbone for Applied Knowledge Graphs (AKGs) as a discipline that focuses on modelling enterprise knowledge in a way that is both operationally useful and semantically rich. AKGs combine explicit structure, domain semantics, metadata, and embeddings into a single connected representation. This combination is exactly what GraphRAG requires: a graph that captures meaning, context, and semantic neighbourhoods while allowing similarity scores and AI-derived intelligence to flow naturally through the graph.
The reason LPG matters is not academic. It matters because the future of enterprise AI depends on the ability to store, query, and reason with knowledge in a way that remains fluid, extensible, interpretable, and implementable on real-world infrastructure. It matters because organisations increasingly require systems that reflect the complexity of the environment they operate in. And it matters because modern data-driven intelligence is fundamentally about connections, not rows, tables, or isolated documents.
