Temporal Semantics in GraphRAG for Legal Documents
Achieving Point-in-Time Accuracy with Labelled Property Graphs and Applied Knowledge Graphs

Table of Contents
Introduction
The Nature of Time in Legal Documents
Why Naive GraphRAG Fails Without Temporal Context
Temporal Modelling in Labelled Property Graphs (LPG)
Applied Knowledge Graph (AKG) Design for Legal Time
Querying for Point-in-Time Accuracy in GraphRAG
Integrating Temporal Reasoning into Large Language Model Pipelines
Implementation Patterns and Practical Trade-offs
RDF-based Knowledge Graphs versus LPG-based Applied Knowledge Graphs
Why the Term “Context Graph” is Misleading
Conclusion
1. Introduction
Legal documents are fundamentally temporal, and each clause, amendment, and reference carries a time dimension that is critical for legal reasoning. Contracts evolve over time, obligations expire, and regulations are amended retroactively. Despite this, many GraphRAG implementations treat legal knowledge bases as static, ignoring temporal constraints. This can result in outputs that are linguistically plausible but factually inaccurate.
For example, asking, “Was Clause 14 of Contract X valid in March 2021?” requires a system that can determine which clauses existed and were effective at that exact point in time. Without explicit temporal modelling, retrieved content may reflect outdated or future clauses, rendering the answer legally unsound.
Labelled Property Graphs (LPGs) offer the ability to attach properties—including temporal attributes—to nodes and relationships. Applied Knowledge Graphs (AKGs) further operationalise this structure by embedding rules, constraints, and retrieval logic to ensure point-in-time determinism. When integrated with GraphRAG, these structures provide temporally accurate, legally defensible context for LLMs.
Temporal modelling must account for three primary aspects: validity intervals, defining when a clause or contract is effective; transaction times, capturing when a record was stored; and event times, marking when legal actions such as amendments occurred. Explicit representation of these times transforms a graph from a passive archive into a powerful operational tool for legal queries.
2. The Nature of Time in Legal Documents
Legal documents are more than static text; they are instruments whose applicability evolves across multiple temporal dimensions. Each clause, amendment, or reference can involve valid time, transaction time, and event time.
Valid Time reflects the period during which a legal statement is effective. For instance, a confidentiality clause may commence on the signing date and expire on contract termination.
Transaction Time records when a change is stored or registered, which is critical for auditing, compliance, and provenance.
Event Time corresponds to when a legal action, such as signing an amendment, actually occurs. Event time may differ from valid time, especially in retroactive amendments.
For illustration, consider a contract scenario:
Contract Signed: 1 January 2020 (Event Time)
Clause Effective: 1 March 2020 (Valid Time)
Amendment Passed: 1 June 2021 (Event Time)
Amendment Retroactive Validity: 1 April 2021 (Valid Time)
Here, the validity of the clause at a query date may not align with either the original signing date or the amendment date, highlighting the need for precise temporal modelling. Overlapping validity periods and retroactive changes add further complexity. Legal structures contain hierarchical timelines: contract-level, clause-level, and relationship-level. Queries that ignore these hierarchies risk returning semantically correct but temporally invalid information.
In GraphRAG, temporal modelling ensures that point-in-time queries return deterministic, auditable results. This enables compliance-grade answers and prevents the generation of misleading LLM outputs.
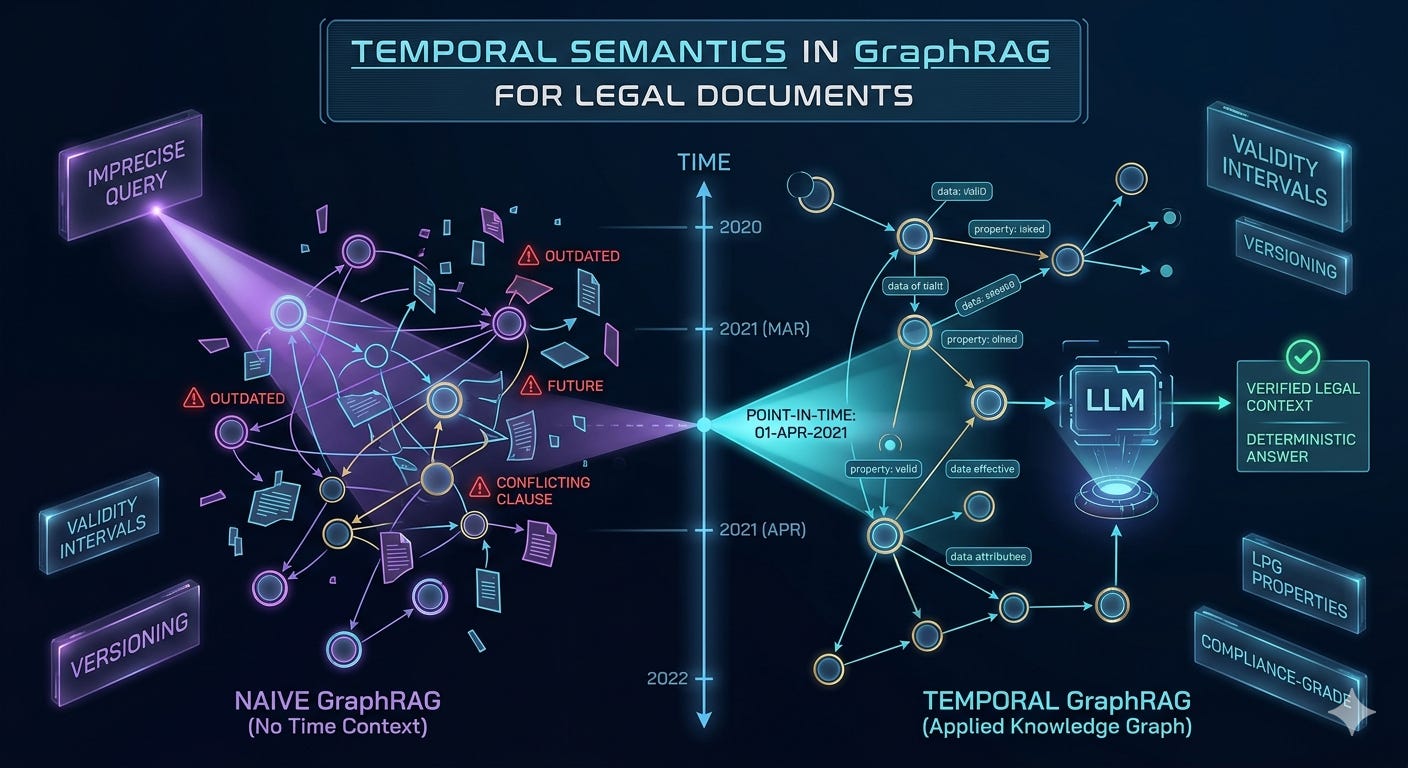
3. Why Naive GraphRAG Fails Without Temporal Context
GraphRAG pipelines typically combine semantic vector similarity with graph traversal. While sufficient for domains with static knowledge, this approach fails in legal reasoning. Without temporal filtering, retrieved clauses may originate from periods that are inconsistent with the query, producing outputs that are plausible but incorrect.
For example, querying, “Which clauses governed liability for Contract X in April 2021?” may return:
Original clauses from 2020
Amendments from 2022
Commentary from 2023
An LLM synthesising this data might produce a hybrid answer that combines clauses across periods, which is legally invalid. The failure here is not semantic but temporal: traversal alone cannot enforce valid-time constraints. Therefore, naive GraphRAG lacks determinism and compliance guarantees.
4. Temporal Modelling in Labelled Property Graphs (LPG)
Labelled Property Graphs provide flexibility to model temporality explicitly. Nodes and relationships can carry valid_from and valid_to properties, allowing traversal queries to filter entities active at a specific time.
Example Clause Node:
CREATE (c:Clause {id: ‘C14’, valid_from: date(’2020-03-01’), valid_to: date(’2021-06-01’)})
Versioned Clause Modelling:
CREATE (clause:Clause {id: ‘C14’})
CREATE (v1:ClauseVersion {version: 1, valid_from: date(’2020-03-01’), valid_to: date(’2021-06-01’)})
CREATE (clause)-[:HAS_VERSION]->(v1)
CREATE (event:AmendmentEvent {date: date(’2021-06-01’), description: ‘Amendment to C14’})
CREATE (v1)-[:AMENDED_BY]->(event)
Event-based modelling allows the system to represent amendments and other legal events as nodes connected to clause versions, capturing both sequence and causality.
Querying clauses valid on a specific date:
MATCH (v:ClauseVersion)
WHERE v.valid_from <= date(’2021-04-01’) AND (v.valid_to IS NULL OR v.valid_to > date(’2021-04-01’))
RETURN v
This query guarantees deterministic point-in-time retrieval. Immutability, explicit intervals, versioning, and consistency are crucial: amendments should not overwrite nodes but create new versions, ensuring historical integrity.
5. Applied Knowledge Graph (AKG) Design for Legal Time
Applied Knowledge Graphs operationalise the temporal structure of LPGs. They prioritise decision-readiness over mere semantic storage. Contract, clause, and party entities are versioned, and relationships carry validity intervals, enabling queries that reflect the system’s state at any point in time.
Each contract node may have multiple ContractVersion nodes, each linked to ClauseVersion nodes. ClauseVersion nodes connect to textual representations or document paragraphs. This design ensures that GraphRAG pipelines retrieve both structured and textual information that is temporally consistent.
AKG example with text linkage:
CREATE (contract:Contract {id:’CX’})
CREATE (cver:ContractVersion {version:’V1’, valid_from: date(’2020-01-01’), valid_to: date(’2021-06-01’)})
CREATE (contract)-[:HAS_VERSION]->(cver)
CREATE (clause:Clause {id:’C14’})
CREATE (clver:ClauseVersion {valid_from: date(’2020-03-01’), valid_to: date(’2021-06-01’)})
CREATE (clause)-[:HAS_VERSION]->(clver)
CREATE (clver)-[:LINKED_TEXT]->(:TextChunk {doc_id:’doc123’, paragraph:14})
This structure allows deterministic retrieval for GraphRAG, ensures auditable history, and supports compliance-grade decision-making.
6. Querying for Point-in-Time Accuracy in GraphRAG
Point-in-time querying ensures the retrieved subgraph represents the world as it existed at a specific date.
Steps
Extract time parameter from user query
Filter nodes and relationships by validity intervals
Resolve conflicts between overlapping versions
Collect linked textual content for GraphRAG
Example Workflow
Query: “What clauses were valid for Contract X in April 2021?”
Graph Query: Filter ClauseVersions with
valid_from <= ‘2021-04-01’ AND (valid_to IS NULL OR valid_to > ‘2021-04-01’)GraphRAG Retrieval: Collect linked text chunks
LLM Input: Only temporally valid clauses
Optimisations
Materialised snapshots: Precompute frequently queried time points
Temporal indices: Ensure queries scale with large legal corpora
Conflict resolution rules: Determine precedence when multiple versions overlap
Correct point-in-time retrieval reduces ambiguity, prevents misleading LLM outputs, and ensures compliance-grade answers.
7. Integrating Temporal Reasoning into Large Language Model Pipelines
Large Language Models (LLMs) cannot reliably infer temporal validity. Integration must externalise temporal reasoning to the graph retrieval layer.
Integration Steps
Temporal intent extraction: Identify relevant dates or periods from query
Graph filtering: Retrieve only temporally valid nodes/relationships
Context construction: Build LLM input using deterministic, temporally scoped subgraph
Prompt design: Explicitly reference time, e.g., “Based on Contract X as of 1 April 2021…”
Additional Techniques
Include version IDs and validity intervals in LLM context
Provide amendment metadata to improve traceability
Optionally enforce symbolic rules to guide retrieval and LLM reasoning
This hybrid approach allows LLMs to focus on synthesis, not temporal inference, which is unreliable in purely generative models.
8. Implementation Patterns and Practical Trade-offs
RDF is widely used for semantic knowledge graphs. It provides formal logic foundations and standardised modelling. Temporal modelling in RDF often relies on:
Reification of triples with attached temporal properties
Named graphs to scope validity
OWL-Time ontology for interval representation
Limitations for Legal GraphRAG
Queries are more complex and less performant than LPG
Graph traversal and temporal filtering require reasoning engines or SPARQL rules
Readability and maintainability are reduced for operational teams
Advantages of LPG-based AKG
Temporal attributes attached directly to nodes/edges
Point-in-time queries are concise and efficient
GraphRAG integration is simpler and more predictable
Example:
(:ClauseVersion {valid_from: date1, valid_to: date2})
LPG-based AKGs better align with enterprise operational needs, ensuring deterministic retrieval and minimal latency, critical for legal compliance systems.
9. RDF-based Knowledge Graphs versus LPG-based Applied Knowledge Graphs
RDF provides a formally defined model for representing knowledge as triples, consisting of subject, predicate, and object. This model is well suited for semantic interoperability, ontology-driven systems, and environments where logical inference and standardisation are primary concerns. In theory, RDF is capable of representing temporal information, but it does not natively support properties on relationships or statements. This limitation becomes particularly relevant when modelling temporal validity in legal documents.
To represent temporal aspects in RDF, additional modelling constructs must be introduced. One common approach is reification, where a statement is transformed into a resource that can then be annotated with temporal properties. Another approach is the use of named graphs, where a set of triples is grouped and associated with metadata such as validity intervals. A more formal approach involves ontologies such as OWL-Time, which define temporal entities and relationships.
A simplified example of RDF reification for a clause validity statement might look as follows:
:stmt1 rdf:type rdf:Statement .
:stmt1 rdf:subject :c14 .
:stmt1 rdf:predicate ex:isValid .
:stmt1 rdf:object true .
:stmt1 ex:validFrom “2020-03-01”^^xsd:date .
:stmt1 ex:validTo “2021-06-01”^^xsd:date .
While this is technically correct, it introduces structural overhead. A single business fact now requires multiple triples and an intermediate node. When scaled across thousands of clauses, amendments, and relationships, this leads to a graph that is significantly more complex to query and maintain.
Named graphs provide an alternative:
GRAPH :validity_2020_2021 {
:c14 ex:isValid true .
}
:validity_2020_2021 ex:validFrom “2020-03-01”^^xsd:date .
:validity_2020_2021 ex:validTo “2021-06-01”^^xsd:date .
However, this approach shifts complexity to query construction. SPARQL queries must explicitly reference graph scopes and temporal metadata, which complicates both development and optimisation.
In contrast, Labelled Property Graphs allow temporal attributes to be attached directly to nodes and relationships. This provides a more direct mapping between the business concept and its representation.
Equivalent LPG representation:
(:ClauseVersion {
id: ‘C14_v1’,
valid_from: date(’2020-03-01’),
valid_to: date(’2021-06-01’)
})
This difference is not merely syntactic. It has several practical consequences for enterprise GraphRAG systems.
First, query complexity is significantly reduced. In LPG, temporal filtering can be expressed as a simple predicate on properties. In RDF, the same query often requires joins across multiple triples, graph scopes, or reified statements.
Second, performance characteristics differ. LPG engines are optimised for traversal with property filtering, which aligns well with point-in-time queries. RDF systems often rely on SPARQL query planning and optional reasoning layers, which can introduce latency, especially in large graphs.
Third, maintainability becomes a critical factor. Engineering teams working with LPG models can reason about the graph structure more intuitively because it aligns closely with domain concepts such as “clause version” or “valid interval”. RDF models, while semantically rich, often require a deeper understanding of ontologies and modelling patterns, which can slow down development in operational environments.
From a GraphRAG perspective, the most important distinction is deterministic retrieval. LPG-based Applied Knowledge Graphs allow temporal constraints to be embedded directly in traversal queries that feed the retrieval pipeline. This ensures that the subgraph provided to the Large Language Model (LLM) is already temporally consistent.
In RDF-based systems, achieving the same level of determinism often requires additional reasoning steps or carefully constructed SPARQL queries. This introduces variability in execution time and increases the risk of incomplete or inconsistent retrievals if queries are not precisely defined.
It is important to emphasise that RDF is not unsuitable for temporal modelling. It is capable, but the cost of expressiveness is complexity. For use cases where formal semantics and interoperability are the primary goals, RDF remains a strong choice. However, in enterprise GraphRAG scenarios focused on performance, determinism, and operational simplicity, LPG-based Applied Knowledge Graphs provide a more pragmatic foundation.
10. Why the Term “Context Graph” is Misleading
The term “Context Graph” has gained popularity in discussions around GraphRAG and Large Language Models. It is often used to describe a graph that provides additional information to support generation. While the term is intuitively appealing, it lacks precise technical meaning and introduces ambiguity when applied to temporal legal reasoning.
The core problem is that “context” is not a well-defined construct in graph modelling. It is typically used as a catch-all term that combines several distinct concerns, including structural relationships, relevance to a query, temporal validity, and provenance of information. Treating these as a single concept obscures the actual requirements for building reliable systems.
In legal GraphRAG, the distinction between context and state is critical. Context is often interpreted as a collection of related information that may help answer a question. State, on the other hand, is a precise and consistent representation of the system at a specific point in time.
A “context graph” in practice often includes:
Historical versions of clauses
Current active clauses
Future amendments
Commentary or annotations
If such a graph is provided to an LLM without temporal filtering, the model receives conflicting signals. For example, a clause that was valid in 2020 and another that replaced it in 2022 may both appear relevant from a semantic perspective. The LLM may then produce an answer that blends these versions, resulting in a response that is coherent but incorrect.
This is not a limitation of the LLM alone. It is a failure of the retrieval layer to provide a consistent input. The LLM operates on the assumption that the provided context is internally consistent. When that assumption is violated, the output cannot be trusted.
To illustrate the issue, consider the difference between two retrieval strategies.
A context-driven approach might execute a query such as:
MATCH (c:Clause)-[:HAS_VERSION]->(v)
WHERE c.id = ‘C14’
RETURN v
This query retrieves all versions of a clause, regardless of their temporal validity. The result is a “context graph” containing multiple, potentially conflicting states.
A state-driven approach introduces temporal constraints:
MATCH (c:Clause)-[:HAS_VERSION]->(v)
WHERE c.id = ‘C14’
AND v.valid_from <= date(’2021-04-01’)
AND (v.valid_to IS NULL OR v.valid_to > date(’2021-04-01’))
RETURN v
This query constructs a point-in-time subgraph, representing the state of the clause at a specific date. The result is deterministic and free of temporal conflicts.
The difference between these two approaches is fundamental. The first relies on the LLM to interpret context and resolve inconsistencies, which it is not designed to do reliably. The second ensures that the input to the LLM is already consistent, allowing the model to focus on synthesis rather than validation.
Another issue with the term “Context Graph” is that it encourages under-modelling. Teams may assume that building a loosely connected graph of related entities is sufficient, without investing in proper temporal modelling, versioning, or validity constraints. This leads to systems that appear to work in simple scenarios but fail under real-world conditions where temporal precision is required.
In enterprise legal applications, this is not acceptable. Queries must be auditable, reproducible, and legally defensible. This requires:
Explicit modelling of temporal validity
Deterministic filtering of nodes and relationships
Clear separation between historical, current, and future states
A more accurate description of what GraphRAG requires is not a “context graph” but a temporally scoped subgraph derived from an Applied Knowledge Graph. This subgraph represents the exact state of the system relevant to the query and serves as the input to the LLM.
Only after this deterministic state is constructed does it become meaningful to refer to the result as context. At that point, context is not a loosely defined collection of information, but a precisely defined dataset that satisfies temporal and structural constraints.
In summary, the term “Context Graph” is misleading because it hides the complexity of temporal reasoning and shifts responsibility to the wrong component. Reliable legal GraphRAG systems are built not on vague notions of context, but on explicit modelling of state, enforced through deterministic retrieval.
11. Conclusion
The central requirement in legal GraphRAG is not relevance, but correctness at a specific point in time. Every query implicitly or explicitly asks for the state of the legal domain at a given date. If temporal semantics are not enforced, the system will return outputs that are linguistically coherent but legally incorrect.
The key idea is straightforward. GraphRAG must not retrieve “relevant context” in a general sense. It must construct a temporally consistent subgraph, representing only the clauses, relationships, and documents that were valid at the requested time. This subgraph is the only acceptable input for a Large Language Model (LLM).
From this perspective, the role of the graph is to guarantee correctness, while the role of the LLM is limited to synthesis and explanation. Any attempt to shift temporal reasoning into the LLM leads to ambiguity and unreliable outputs.
The comparison between RDF-based Knowledge Graphs and Labelled Property Graph based Applied Knowledge Graphs reinforces this. RDF can model temporal semantics, but often at the cost of complexity, query overhead, and reduced operational clarity. LPG-based AKGs provide a more direct and efficient way to encode validity intervals and execute point-in-time queries, which is critical for GraphRAG pipelines in enterprise environments.
The same principle applies to the notion of a “Context Graph”. This term is misleading because it suggests that collecting related information is sufficient. In legal use cases, it is not. What matters is not context, but state. A graph that includes multiple temporal versions without filtering is not useful input, it is a source of error.
The correct pattern is therefore:
Encode temporal validity explicitly in the graph
Enforce time constraints during retrieval
Construct a deterministic, point-in-time subgraph
Use this subgraph as the sole input to the LLM
When this pattern is applied, GraphRAG produces outputs that are temporally accurate, auditable, and suitable for legal and compliance use. Without it, the system remains a semantic search tool with no guarantees of correctness.